SirixDB keeps storage space to a minimum while retaining the full history of your data.
It allows time-travel queries on its binary XML and JSON encoding.
It is released for free under The 3-Clause BSD License license. Have fun!
Keep the full history of your data for time travel analysis, audits, to correct human or application errors...
SirixDB keeps storage space to a minimum while supporting the reconstruction of any revision in linear time.
Furthermore, it allows time travel queries such that you can analyze the history of your data efficiently to predict the future or for audits.
Not enough? What about correcting any human or application errors or comparing any revision of your XML or JSON documents efficiently?
Supported by
![]()
SirixDB is supported by YourKit: YourKit supports open-source projects with innovative and intelligent tools for monitoring and profiling Java and .NET applications. YourKit is the creator of YourKit Java Profiler, YourKit .NET Profiler, and YourKit YouMonitor.
SirixDB is supported by JetBrains. They support Open Source with licenses for their products and we love Kotlin.
Compact snapshots / efficient time-travel queries
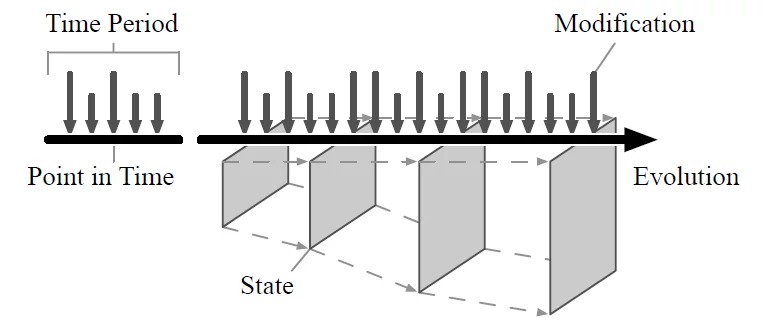
The following time-travel query to be executed on our binary JSON representation of Twitter sample data gives an initial impression of what's possible:
let $doc := jn:open('database','resource', xs:dateTime('2019-04-13T16:24:27Z'))
let $statuses := $doc.statuses
let $foundStatus := for $status in $statuses
let $dateTimeCreated := xs:dateTime($status.created_at)
where $dateTimeCreated > xs:dateTime("2018-02-01T00:00:00")
and not(exists(jn:previous($status)))
order by $dateTimeCreated
return $status
return {"revision": sdb:revision($foundStatus), $foundStatus{text}}
The query opens a database and therein a resource in a specific revision based on a timestamp (2019–04–13T16:24:27Z) and searches for all statuses, which have a created_at timestamp, that has to be greater than the 1st of February in 2018 and did not exist in the previous revision. . is a dereferencing operator used to dereference keys in JSON objects. Array values can be accessed as shown or through specifying an index, starting with zero: array[[0]], for instance, specifies the first value of the array.
Lightweight Buffer Manager
Page-fragments are referenced using in-memory references and a lightweight buffer manager, which can reclaim the used heap space, once a page has to be evicted.
No Write-Ahead-Log (WAL) needed
An UberPage is the main entry point into a resource. It is swapped atomically as the last action of a commit.
Persistent Tree-Structure With Variable Sized Pages
SirixDB uses variable-sized page-fragments, stored in a huge persistent and durable tree-structure for indexing revisions as well as data and the nodes of secondary indexes.
Versioning
SirixDB versions data and index structures on a per revision and record level. As such, versioning takes place at a fine-granular level. Furthermore, through a novel versioning algorithm called sliding snapshot, it can avoid write and read peaks.
Time travel queries
SirixDB allows sophisticated time travel queries such that you can analyze the history of your data or retrieve the differences efficiently.
XML / JSON
You decide how your data looks like and which format fits best. SirixDB currently supports both the import of XML as well as JSON data.
Powerful APIs

REST
SirixDB provides an asynchronous, RESTful API, which is non-blocking. It is built with Vert.x, Kotlin (coroutines) and Keycloak.

XQuery / JSONiq
Several extensions to an XQuery-processor called Brackit are available. SirixDB, for instance, supports navigation via additional temporal XPath axes or XQuery functions for JSON data to navigate not only in space but also in time. Furthermore, SirixDB offers several additional precompiled functions to simplify the analysis of your temporal data. The API also provides a very convenient way to interact with SirixDB. Think of it as an in-memory representation of a DOM.

Transactional cursor API
SirixDB provides a transactional low-level, cursor-based API which is very powerful. SirixDB not only provides standard XPath axes. It also provides additional temporal enhancements to navigate in time. Furthermore, several other axes, for instance, a LevelOrder axis, a PostorderAxis, and a DescendantAxis, which can skip whole subtrees, exists. Additionally, SirixDB provides several filters, a NestedAxis, a PredicateAxis and much more.

Diffing-API
SirixDB provides a way to import several revisions of an XML document with the help of a diffing algorithm called Fast Matching Simple EditScript. With the help of this diffing-algorithm, SirixDB can store the encountered differences in the tree structures instead of storing the whole revision.
Once you've stored several revisions in SirixDB, either through the import based on the diffing algorithm or simply through working with SirixDB in the first place, you can quickly compute diffs between any two revisions. SirixDB makes use of its stable node identifiers and optionally stored hashes. Each time the hashes of two nodes are equal, the whole subtrees in both revisions can be skipped while traversing both tree structures.
Ready for using SirixDB?
Give it a try and let us know your thoughts.